
Việt Nam ghi tên vào cuộc đua phát triển AI tổng quát tại châu Á
Tờ Nikkei Asia nhận định, Việt Nam đã ghi tên vào cuộc đua phát triển các chương trình trí tuệ nhân tạo tổng quát phục vụ cho ngôn ngữ và văn hóa địa phương ở châu Á, với ViGTP - chương trình AI phát triển bởi VinBigData (VBD).
Thị trường toàn cầu về AI tổng hợp đang mở rộng 42% mỗi năm, theo ước tính từ Bloomberg Intelligence, dự kiến sẽ đạt 1,3 nghìn tỷ USD vào năm 2032, gấp khoảng 32 lần quy mô 40 tỷ USD của năm 2022.
Dẫn đầu là các công ty công nghệ của Mỹ, như OpenAI, Google và Amazon - những gã khổng lồ công nghệ có nguồn vốn và nhân lực dồi dào.
Vũ Hà Văn, giáo sư toán học tại Đại học Yale, đang giữ vai trò giám đốc khoa học VBD cho biết: Bất chấp sự cạnh tranh sâu sắc, VinGroup đã chọn phát triển phiên bản độc lập, với dữ liệu của Việt Nam để tạo ra AI có độ chính xác cao hơn đối thủ nước ngoài.
Đến nay, các chương trình AI tạo sinh chủ yếu đào tạo trên dữ liệu tiếng Anh. Điều đó có nghĩa là có tương đối ít dữ liệu từ Việt Nam, làm giảm độ chính xác của các chương trình đó khi nói đến văn hóa, lịch sử và luật pháp địa phương.
Mô hình ngôn ngữ lớn (LLM) của ViGPT được cho bao gồm 1,6 tỷ tham số, tương đương vài phần trăm kích thước của GPT-4 của OpenAI.
Nhiều thông số hơn thường tương đương với trí thông minh cao hơn. Nhưng theo bài đánh giá AI tổng quát tuỳ chỉnh đối với thị trường Việt Nam, ViGPT vượt trội hơn nhiều đối thủ nước ngoài và đạt được số điểm chỉ đứng sau ChatGPT.
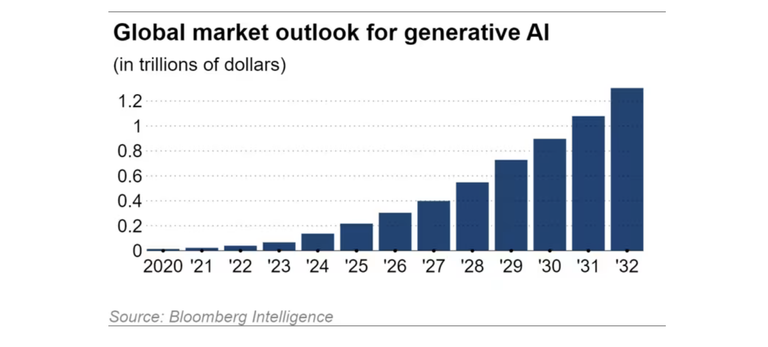
Triển vọng giá trị thị trường AI tạo sinh đến năm 2032.
Tập đoàn VinFast sẽ áp dụng công nghệ AI vào sản xuất xe điện. Người lái xe sẽ có thể điều khiển phương tiện thông qua mệnh lệnh bằng lời nói tiếng Việt. Tập đoàn cũng có kế hoạch kết hợp AI vào lĩnh vực tài chính, bảo hiểm và hậu cần.
Cuộc đua phát triển AI tại châu Á
Ước tính chỉ có khoảng 5% dân số toàn cầu nói tiếng Anh như ngôn ngữ đầu tiên, nghĩa là có nhu cầu tiềm ẩn lớn về AI được phát triển cho những người không nói tiếng Anh bản xứ.
Tại Nhật Bản, các công ty đang phát triển AI tạo ra tiếng Nhật. Vào tháng 8, tập đoàn điện tử NEC đã triển khai dịch vụ sử dụng LLM cotomi. Công ty viễn thông NTT sẽ bắt đầu dịch vụ vào tháng 3 dựa trên tsuzumi, một LLM khác. Nhà cung cấp dịch vụ di động Nhật Bản SoftBank, cũng đang phát triển LLM của riêng mình.
“Hiểu được các hoạt động kinh doanh của Nhật Bản mang lại lợi thế về khả năng sử dụng, chẳng hạn như trả lời email và thực hiện công việc của trung tâm cuộc gọi một cách tự nhiên hơn”, Chủ tịch SoftBank Junichi Miyakawa cho biết.
Thúc đẩy cuộc đua phát triển AI bản địa hóa là những rủi ro do quá phụ thuộc vào Mỹ, đặc biệt là khi nói đến khả năng cạnh tranh quốc tế và an ninh quốc gia. Cũng có lo ngại rằng việc sử dụng các chương trình AI được phát triển ở quốc gia khác sẽ dẫn đến vi phạm dữ liệu, ảnh hưởng đến thông tin nhạy cảm.
Giáo sư Văn cho hay, không nên để lĩnh vực công nghệ mới nổi vào tay các công ty nước ngoài vì ngày càng nhiều sinh viên sử dụng AI để học tập, đồng nghĩa sự đổi mới có ảnh hưởng rất lớn đến thế hệ trẻ.
Tại Trung Quốc, nơi đang cạnh tranh công nghệ với Mỹ, Baidu, Tencent Holdings và Alibaba Group Holding đang phát triển AI sáng tạo. Ernie Bot của Baidu tự hào có hơn 100 triệu người dùng tính đến cuối năm ngoái.
Chủ tịch kiêm Giám đốc điều hành Baidu Robin Li cho biết: “Mô hình ngôn ngữ lớn được tạo ra mà chúng tôi đang phát triển hiện nay sẽ phù hợp hơn với ngôn ngữ Trung Quốc và thị trường Trung Quốc”.
Tháng 8 năm ngoái, công ty dịch vụ mạng Naver của Hàn Quốc đã tiết lộ HyperClova X, AI tổng hợp được tùy chỉnh cho ngôn ngữ Hàn Quốc. Chương trình sẽ được tích hợp với công cụ tìm kiếm và nền tảng mua sắm trực tuyến của công ty để cho phép người dùng tìm thấy kết quả họ muốn một cách hiệu quả hơn.
Naver cho biết cơ sở dữ liệu tiếng Hàn của họ lớn hơn 6.500 lần so với dữ liệu tiếng Hàn của ChatGPT, giúp tạo ra văn bản đọc tự nhiên hơn và nhận dạng ngôn ngữ mượt mà hơn.
Tháng trước, Singapore đã công bố kế hoạch phát triển LLM phù hợp với các ngôn ngữ Indonesia, Malaysia và Thái Lan. Tuy nhiên, những sáng kiến như vậy sẽ phải đối mặt với những thách thức, chẳng hạn như thiếu dữ liệu có thể đào tạo bằng các ngôn ngữ ít được sử dụng và lợi nhuận từ việc phát triển các mô hình như vậy.
Thế Vinh - https://vietnamnet.vn/viet-nam-ghi-ten-vao-cuoc-dua-phat-trien-ai-tong-quat-tai-chau-a-2243193.html







